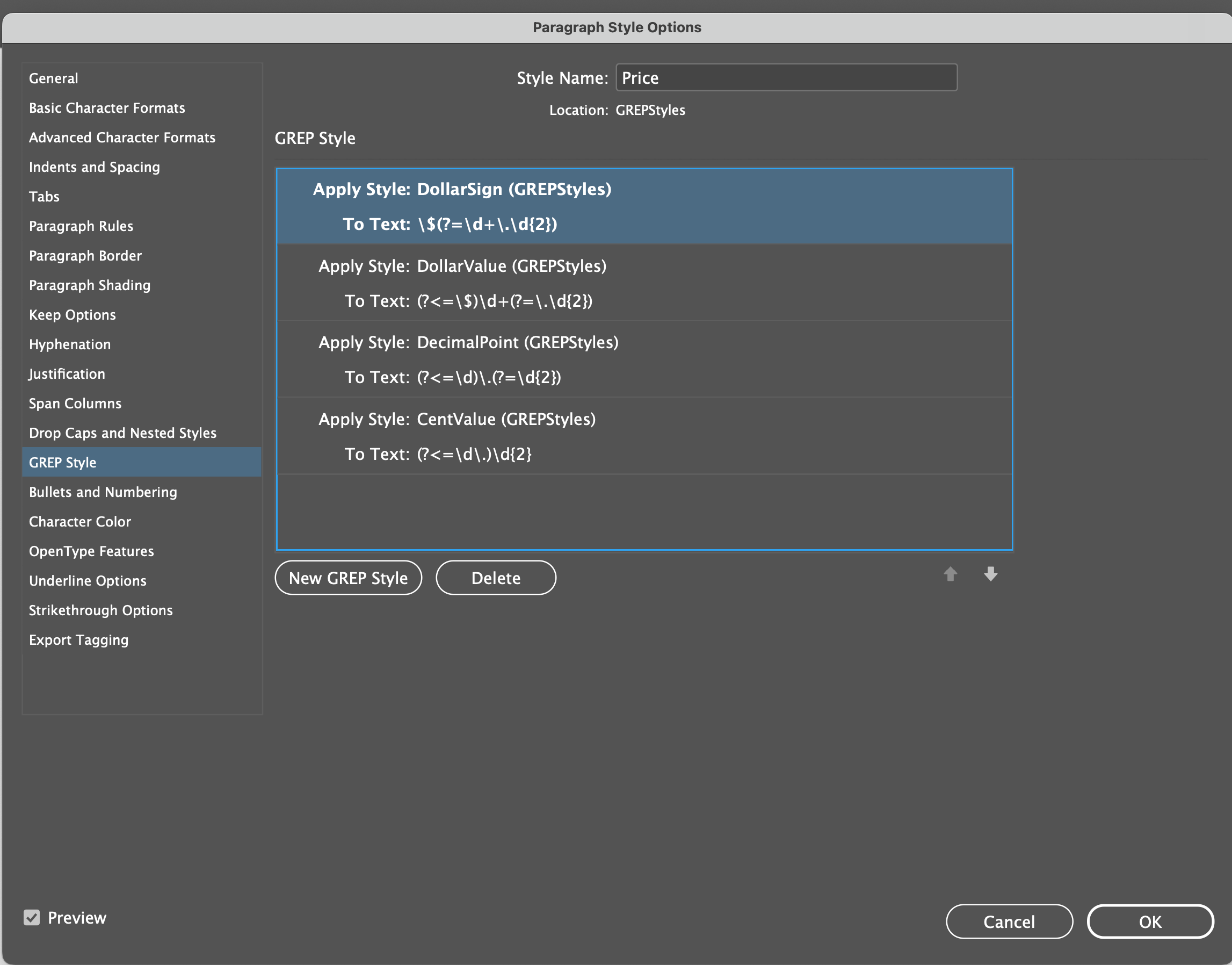
The Tightener project is still moving forward. I’ve just released alpha version 0.0.8.
Tightener is ‘automation glue’ – it ties together all kinds of computer softwares and allows them to interact in a structured and efficient manner.
Tightener is a developer’s tool – it lives in the background and allows developers to integrate disparate systems.
Watch this little Youtube demo (skip to time stamp 08:00 if you don’t want to see the intro):
https://www.youtube.com/watch?v=_r55k54AuBA
https://github.com/zwettemaan/TightenerDocs/wiki/Tightener-Architecture
This example shows how Tightener is used to make a bridge between Jupyter Notebooks (https://jupyter.org/ – originally from the Python world), and ExtendScript or UXPScript in InDesign.
This combo of Jupyter Notebooks and ExtendScript allows would-be scripters a much smoother way to ‘get into’ scripting.
For someone new to scripting, using Jupyter Notebooks is much more ‘natural’, interactive and instructive than using more specialized tools like Visual Studio Code.
Personally, I use Jupyter Notebooks during the ‘first figure it out’ phases of a new project. Once the basic ingredients have been determined, I’ll switch to Visual Studio Code for the actual system building.
Yes, I know, installing Python3 and Jupyter Notebooks is not really straightforward in its own right, and that presents a different kind of threshold, but once they’re installed, trying out scripts and script statements is much easier.
You can download an alpha version of Tightener from the Github repo:
https://github.com/zwettemaan/TightenerDocs
Version 0.0.8 has a link here:
https://github.com/zwettemaan/TightenerDocs/tree/main/Releases/Alpha
Other Stuff
Other things that are new to the 0.0.8 release: I’ve open-sourced and moved all of the supporting code for Tightener (scripts, plug-ins, and so on) into the TightenerDocs repo on Github, so you can now inspect or access a lot of the source code that makes Tightener ‘tick’.
For example, have a look here:
https://github.com/zwettemaan/TightenerDocs/tree/main/CurrentRelease/CommandLine/Scripts
https://github.com/zwettemaan/TightenerDocs/tree/main/CurrentRelease/SampleScripts
Next Steps
I’ll now turn my attention to the licensing module of Tightener. I want to make it easy for scripters to protect and monetize their work, without having to wrestle with complicated packaging and publishing rules, and Tightener will be instrumental in achieving that.
The basic idea is that Tightener will protect scripts by giving the developer multiple choices – for example: a developer could opt to never physically copt their script onto end-users computers. Tightener would only retrieve the script from the developer’s own server when the end-user computer is licensed to do so and the script would never be saved to disk, which would help in protecting the script against downloading and reverse engineering.
The Tightener licensing module will take care of ‘uniquenizing’ the end-user computer and checking licensing allowances before allowing scripts to run…
More info to come…